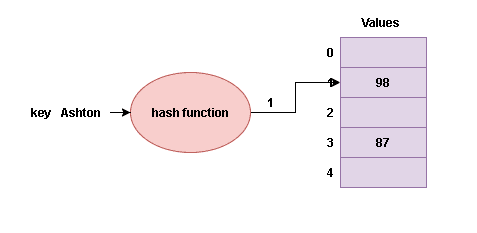
In this article, we will learn to implement a hash table using a singly linked list. A hash table is a data structure that stores items in an array of buckets/ slots. It has a hash function that takes a key as an input and generates an index into an array of buckets. We put the value of the key at that index. Let’s say we want to store scores of students in a hash table. We will pass the name as a key to the hash function, and it will output the index. Then, we will store the score at that index. Later, if we want some student’s score, we will call the hash function with that key (name), and it will give us its location in the array.
But what if the hash function generates the same index for two different names (keys). Then, there will be a collision. To handle that, we will use the separate chaining method. Each array item points to a singly linked list, which contains (key, value) pairs. Moreover, nodes in the same linked list have the same hash code (index). Consider the following figure to understand this concept.
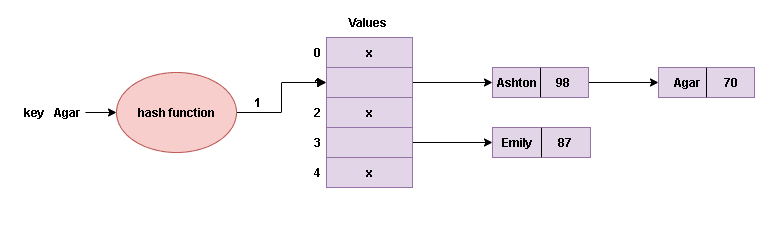
Implementation of Hash Tables Chaining with Singly Linked Lists
Let’s now go ahead and implement hash tables chaining with singly-linked lists. It will have the following functionalities.
- Insert: It takes a key and a value. If the key already exists, then it updates the value. Otherwise, it adds a new item.
- Delete: It takes a key and removes an item with that key. It also returns the value of the deleted item. If no element with the given key exists, it throws an error.
- Search: The input is a key, and the output is the value of that key. If not found, then an error gets thrown.
- Traverse: It displays all (key, value) pairs.
The code is given below.
class Node:
def __init__(self, key=None, value=None):
self.key = key
self.value = value
self.next = None
#implementation of linked list for the hash table
class LinkedList:
def __init__(self):
self.head = None
#add or update a node, return 0 if node added and 1 if node updated
def insert(self, key, value):
node = Node(key, value) #create a node
if self.head == None: #if list is empty insert a node at the start
self.head = node
return 0
else:
temp = self.head
#iterate through the list till last node is found or key already exists
while temp.next:
if temp.key == key: #update value if key already exists
temp.value = value
return 1
else:
temp = temp.next
if temp.key == key: #update value if key already exists
temp.value = value
return 1
temp.next = node #adding a new node
return 0
#find a node with the key in the list or throw an error
def search(self, key):
temp = self.head
#iterate through the list
while temp:
if temp.key == key:
return temp.value
else:
temp = temp.next
raise KeyError(f'Item with the key {key} does not exist')
#remove the node with the given key from the list or throw an error
def delete(self, key):
if self.head: #if the list is not empty
if self.head.key == key: #if the node to be deleted is the first node
value = self.head.value
self.head = self.head.next
return value
else:
temp = self.head
#iterate through the list
while temp.next:
if temp.next.key == key:
value = temp.next.value
temp.next = temp.next.next
return value
else:
temp = temp.next
raise KeyError(f'Item with the key {key} does not exist')
def traverse(self):
temp = self.head
while temp:
print(f"{temp.key}\t{temp.value}")
temp = temp.next
class HashTable:
def __init__(self):
self.capacity = 10 #maximum size of the array of buckets
self.length = 0 #length of inserted items
self.buckets = [LinkedList() for i in range(0, self.capacity)]
#get the length
def len(self):
return self.length
def hash(self, key): #get the index into an array of buckets
return hash(key)%self.capacity
def insert(self, key, value): #insert or update an item
index = self.hash(key)
add = self.buckets[index].insert(key, value)
if add == 0: #increase the length if new item is added
self.length += 1
def search(self, key): #find the value of the given item
index = self.hash(key)
return self.buckets[index].search(key)
def delete(self, key): #remove the item and return its value
index = self.hash(key)
value = self.buckets[index].delete(key)
if value:
self.length -= 1
return value
def traverse(self): #print all the (key, value) pairs
for i in range(0, self.capacity):
self.buckets[i].traverse()
ht = HashTable() #create a hash table
print("Length:", ht.len())
ht.insert("ashton", 99) #add a new item
ht.insert("agar", 87) #add a new item
ht.insert("emily", 90) #add a new item
ht.insert("agar", 89) #update
key = "emily"
print(f"The score of {key} is {ht.search(key)}") #searching score
print(f"The score of deleted item with name/key {key} is {ht.delete(key)}") #deleting item
print("Length:", ht.len())
print("Get all items")
ht.traverse()
Output
Length: 0 The score of emily is 90 The score of deleted item with name/key emily is 90 Length: 2 Get all items agar 89 ashton 99